In-Depth Comparison of st Reliability Algorithms over Uncertain Graphs
An In-Depth Comparison of s-t Reliability Algorithms
over Uncertain Graphs
A summary of the PVLDB 2019 research paper by Xiangyu Ke, Arijit Khan, and Leroy Lim Hong Quan
Uncertain, or probabilistic, graphs have been increasingly used to represent noisy linked data in many emerging applications, and have recently attracted the attention of the database research community [7]. A fundamental problem on uncertain graphs is the s-t reliability, which measures the probability that a target node t is reachable from a source node s in a probabilistic (or uncertain) graph, i.e., a graph where every edge is assigned a probability of existence. This s - t reliability estimation has been used in many applications such as measuring the quality of connections between two terminals in a sensor network, finding other proteins that are highly probable to be connected with a specific protein in a protein-protein interaction (PPI) network, identifying highly reliable peers containing some file to transfer in a peer-to-peer (P2P) network, probabilistic path queries in a road network, and evaluating information diffusion in a social influence network.
Due to the inherent complexity of the problem (#
P-hard),
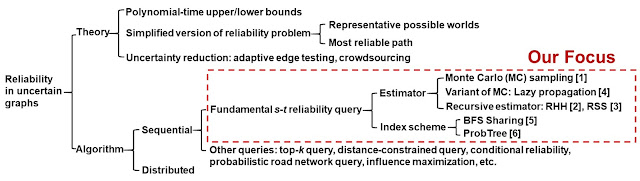
although the exact reliability detection has received attention in the
past, the focus nowadays has mainly been on approximate and heuristic solutions over large-scale graphs. The large spectrum of the reliability problem is categorized in Figure 1. Notice that in this work, we have focused on sequential algorithms for the fundamental s-t reliability query. In particular, various sampling and indexing based efficient algorithms were proposed in the literature. Estimation of reliability in uncertain graphs has its beginnings with the
usage of Monte Carlo (MC) sampling [1]. Subsequently, more
advanced sampling methods were proposed in the form of recursive samplings [2, 3], lazy propagation sampling [4], and shared possible worlds [5], as well as
other indexing methods [6]. With the wide range of algorithms
available for estimating the s-t reliability over uncertain graphs,
there is an urgent need to realize their trade-offs, and to employ the
best algorithm for a given scenario.
As depicted in Figure 2, we find serious concerns in the existing experimental comparisons of state-of-the-art reliability estimation algorithms over uncertain graphs. (1) There is no prior work that compared all state-of-the-art methods with each other. It is, therefore, difficult to draw a general conclusion on the superiority and trade-offs of different methods. (2) As shown in Figure 2, with the exception of [4], other experimental studies in [2, 3, 5, 6] either considered a fixed number of samples (e.g., 1000), or the maximum number of samples was limited by 2000. However, we observe in our experiments that the number of samples necessary for the convergence of reliability estimation varies a lot depending on the specific algorithm used (e.g., for Recursive Stratified Sampling [3], #samples required for convergence is 250∼1000, while for Lazy Propagation [4], it is 500∼1500), and also on the underlying characteristics of the uncertain graph dataset. Therefore, the running time necessary to achieve convergence (and hence, good-quality results) should be reported differently, as opposed to using the same number of samples in all experiments. (3) The metrics used for empirically comparing these techniques were not consistent in the past literature, thereby making them apple-to-orange comparisons in the larger context. For example, [3] measured relative variance of different estimators and their running times for the same number of samples (2000). In both [5, 6], the authors reported accuracy (with respect to baseline MC sampling) and running times of different algorithms using a maximum of 1000 samples. On the other hand, [2] compared relative variance, accuracy, and running times of various estimators by considering a fixed (1000) number of samples. In addition, surprisingly none of these studies reported the online memory usage which, according to our experiments, varied a great extent. (4) Last but not least, we find certain errors and further optimization scopes in past algorithms (e.g., accuracy of [4], time complexity analysis of [5]), and by correcting (or, updating) them we significantly improve their performance.
 Figure 2: State-of-the-art reliability estimation algorithms in uncertain graphs: A directed arrow depicts reported superiority in prior
works. All algorithms have not been thoroughly compared with each
other. Moreover, previous works did not employ identical frameworks,
datasets, and metrics for comparison. Thus, it is critical to investigate
their trade-offs and superiority over each other.
Figure 2: State-of-the-art reliability estimation algorithms in uncertain graphs: A directed arrow depicts reported superiority in prior
works. All algorithms have not been thoroughly compared with each
other. Moreover, previous works did not employ identical frameworks,
datasets, and metrics for comparison. Thus, it is critical to investigate
their trade-offs and superiority over each other.
Through our systematic and in-depth analysis of experimental results, we report surprising findings, such as many follow-up algorithms can actually be several orders of magnitude inefficient, less accurate, and more memory intensive compared to the one s that were proposed earlier. Our findings can be summarized as follows.
For estimator variance, both recursive methods: RHH and RSS exhibit significantly better performance than other four MC-based approaches: MC, BFSSharing, ProbTree, and LP+. Methods in the same category share very similar variance. In general, RSS is the best regarding variance, and achieves fastest convergence. To achieve convergence, there is no single sample size K that can be used across various datasets and estimators. Usually recursive methods require about 500 less samples than MC-based methods on the same dataset.
For accuracy, all methods have similar relative error (<1.5%) at convergence. If K is set as 1000 for all estimators, some of them might not reach convergence, thus their relative errors can further be reduced by using larger K until convergence.
For efficiency, RHH and RSS are the fastest when running time is measured at convergence. When K is set as 1000, there is no common winner in terms of running time. Overall, the running times of RHH, RSS, ProbTree, and LP+ are comparable. BFSSharing is 4× slower than MC, since it estimates all nodes’ reliability from the source node.
The memory usage ranking (in increasing order of memory) is: MC < LP+ < ProbTree < BFSSharing < RHH ≈ RSS.

Recommendation. Table 1 summarizes the recommendation level of each method according to different performance metrics. The scale is from 1 to 4 stars, and larger star number stands for higher ranking. Clearly, there is no single winner. Considering various trade-offs, in conclusion we recommend ProbTree for s-t reliability estimation. It provides good performance in accuracy, online running time, and memory cost. Its index can slightly reduce the variance, compared to other MC-based estimators. Notably, we adopted MC as ProbTree’s reliability estimating component (as the original paper [6] did). However, one can replace this with any other estimator (e.g., recursive estimators: RHH and RSS) to further improve ProbTree’s efficiency and to reduce its variance (as demonstrated in our paper).
The decision tree shown in Figure 3 demonstrates our recommended strategy for estimator selection under different constraints. Following the branch with red tick, the better estimator(s) under the current condition can be determined. Notice that the path from the root to the leaf of ProbTree consists of all red ticks, indicating its applicability and trade-off capacity considering various factors.
[Reference]
[1] G. S. Fishman. A Comparison of Four Monte Carlo Methods for Estimating the Probability of s-t Connectedness. IEEE Tran. Rel., 1986.
A summary of the PVLDB 2019 research paper by Xiangyu Ke, Arijit Khan, and Leroy Lim Hong Quan
Uncertain, or probabilistic, graphs have been increasingly used to represent noisy linked data in many emerging applications, and have recently attracted the attention of the database research community [7]. A fundamental problem on uncertain graphs is the s-t reliability, which measures the probability that a target node t is reachable from a source node s in a probabilistic (or uncertain) graph, i.e., a graph where every edge is assigned a probability of existence. This s - t reliability estimation has been used in many applications such as measuring the quality of connections between two terminals in a sensor network, finding other proteins that are highly probable to be connected with a specific protein in a protein-protein interaction (PPI) network, identifying highly reliable peers containing some file to transfer in a peer-to-peer (P2P) network, probabilistic path queries in a road network, and evaluating information diffusion in a social influence network.

Figure 1: The broad spectrum of reliability problem over uncertain graphs
As depicted in Figure 2, we find serious concerns in the existing experimental comparisons of state-of-the-art reliability estimation algorithms over uncertain graphs. (1) There is no prior work that compared all state-of-the-art methods with each other. It is, therefore, difficult to draw a general conclusion on the superiority and trade-offs of different methods. (2) As shown in Figure 2, with the exception of [4], other experimental studies in [2, 3, 5, 6] either considered a fixed number of samples (e.g., 1000), or the maximum number of samples was limited by 2000. However, we observe in our experiments that the number of samples necessary for the convergence of reliability estimation varies a lot depending on the specific algorithm used (e.g., for Recursive Stratified Sampling [3], #samples required for convergence is 250∼1000, while for Lazy Propagation [4], it is 500∼1500), and also on the underlying characteristics of the uncertain graph dataset. Therefore, the running time necessary to achieve convergence (and hence, good-quality results) should be reported differently, as opposed to using the same number of samples in all experiments. (3) The metrics used for empirically comparing these techniques were not consistent in the past literature, thereby making them apple-to-orange comparisons in the larger context. For example, [3] measured relative variance of different estimators and their running times for the same number of samples (2000). In both [5, 6], the authors reported accuracy (with respect to baseline MC sampling) and running times of different algorithms using a maximum of 1000 samples. On the other hand, [2] compared relative variance, accuracy, and running times of various estimators by considering a fixed (1000) number of samples. In addition, surprisingly none of these studies reported the online memory usage which, according to our experiments, varied a great extent. (4) Last but not least, we find certain errors and further optimization scopes in past algorithms (e.g., accuracy of [4], time complexity analysis of [5]), and by correcting (or, updating) them we significantly improve their performance.

Through our systematic and in-depth analysis of experimental results, we report surprising findings, such as many follow-up algorithms can actually be several orders of magnitude inefficient, less accurate, and more memory intensive compared to the one s that were proposed earlier. Our findings can be summarized as follows.
For estimator variance, both recursive methods: RHH and RSS exhibit significantly better performance than other four MC-based approaches: MC, BFSSharing, ProbTree, and LP+. Methods in the same category share very similar variance. In general, RSS is the best regarding variance, and achieves fastest convergence. To achieve convergence, there is no single sample size K that can be used across various datasets and estimators. Usually recursive methods require about 500 less samples than MC-based methods on the same dataset.
For accuracy, all methods have similar relative error (<1.5%) at convergence. If K is set as 1000 for all estimators, some of them might not reach convergence, thus their relative errors can further be reduced by using larger K until convergence.
For efficiency, RHH and RSS are the fastest when running time is measured at convergence. When K is set as 1000, there is no common winner in terms of running time. Overall, the running times of RHH, RSS, ProbTree, and LP+ are comparable. BFSSharing is 4× slower than MC, since it estimates all nodes’ reliability from the source node.
The memory usage ranking (in increasing order of memory) is: MC < LP+ < ProbTree < BFSSharing < RHH ≈ RSS.
Table 1: Summary and recommendation

Figure 3: The decision tree for selecting a proper reliability estimator under different scenarios
Recommendation. Table 1 summarizes the recommendation level of each method according to different performance metrics. The scale is from 1 to 4 stars, and larger star number stands for higher ranking. Clearly, there is no single winner. Considering various trade-offs, in conclusion we recommend ProbTree for s-t reliability estimation. It provides good performance in accuracy, online running time, and memory cost. Its index can slightly reduce the variance, compared to other MC-based estimators. Notably, we adopted MC as ProbTree’s reliability estimating component (as the original paper [6] did). However, one can replace this with any other estimator (e.g., recursive estimators: RHH and RSS) to further improve ProbTree’s efficiency and to reduce its variance (as demonstrated in our paper).
The decision tree shown in Figure 3 demonstrates our recommended strategy for estimator selection under different constraints. Following the branch with red tick, the better estimator(s) under the current condition can be determined. Notice that the path from the root to the leaf of ProbTree consists of all red ticks, indicating its applicability and trade-off capacity considering various factors.
For more information, click here for our paper. Codebase: GitHub
Blog post contributed by: Xiangyu Ke and Arijit Khan
Blog post contributed by: Xiangyu Ke and Arijit Khan
[1] G. S. Fishman. A Comparison of Four Monte Carlo Methods for Estimating the Probability of s-t Connectedness. IEEE Tran. Rel., 1986.
[2] R. Jin, L. Liu, B. Ding, and H. Wang. Distance-Constraint
Reachability Computation in Uncertain Graphs. PVLDB,
4(9):551–562, 2011.
[3] R. Li, J. X. Yu, R. Mao, and T. Jin. Recursive Stratified
Sampling: A New Framework for Query Evaluation on
Uncertain Graphs. IEEE TKDE, 28(2):468–482, 2016
[4] Y. Li, J. Fan, D. Zhang, and K.-L. Tan. Discovering Your
Selling Points: Personalized Social Influential Tags
Exploration. In SIGMOD, 2017.
[5] R. Zhu, Z. Zou, and J. Li. Top-k Reliability Search on
Uncertain Graphs. In ICDM, 2015.
[6] S. Maniu, R. Cheng, and P. Senellart. An Indexing
Framework for Queries on Probabilistic Graphs. ACM Trans.
Database Syst., 42(2):13:1–13:34, 2017.
[7] A. Khan, Y. Ye, and L. Chen. On Uncertain Graphs.
Synthesis Lectures on Data Management. Morgan &
Claypool Publishers, 2018.

Comments
Post a Comment