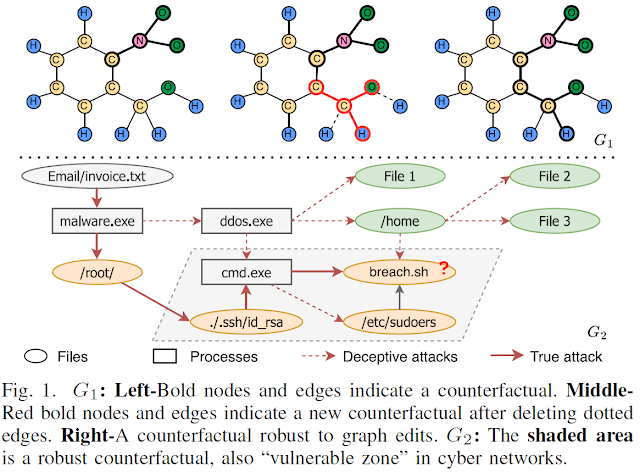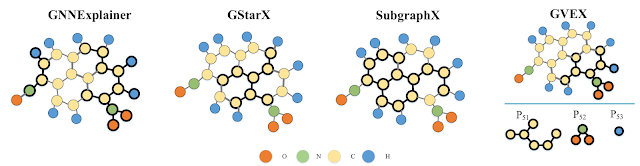
View-based Explanations for Graph Neural Networks A summary of the SIGMOD 2024 research paper by Tingyang Chen, Dazhuo Qiu, Yinghui Wu, Arijit Khan, Xiangyu Ke, and Yunjun Gao Background [Graph Classification, Graph Neural Networks, and Explainability]. Graph classification is essential for several real-world tasks such as drug discovery, text classification, and recommender system [1, 2, 3]. The rising graph neural networks (GNNs) have exhibited great potential in graph classification across many real domains, e.g., social networks, chemistry, and biology [4, 5, 6, 7]. Given a database G as a set of graphs, and a set of class labels Ł, GNN-based graph classification aims to learn a GNN as a classifier M, such that each graph 𝐺 ∈ G is assigned a correct label M ( 𝐺 ) ∈ Ł . GNNs are “black-box” — it is inherently difficult to understand which aspects of the input data drive the decisions of the network. Explainability can improve the model’s transparency rela...