Mining Top-k Pairs of Correlated Subgraphs in a Large Network
Mining Top-k Pairs
of Correlated Subgraphs in a Large Network
A summary of the VLDB
2020 research paper by Arneish Prateek, Arijit Khan,
Akshit Goyal, and Sayan Ranu
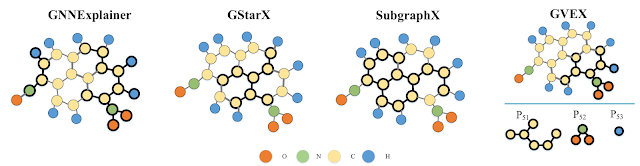
[Background and Problem] A large body of work exists on mining recurring structural patterns among a group of nodes in the form of frequent subgraphs [1, 2]. However, can we mine recurring patterns among the frequent subgraphs themselves? In this paper, we explored this question by mining correlated pairs of frequent subgraphs. Correlated subgraphs are different from frequent subgraphs due to the flexibility in connections between constituent subgraph instances. To elaborate, in Figure 1, we highlight three regions inside the chemical structure of Taxol, an anti-cancer drug, where CCCH and O occur closely albeit connected in different ways in all three instances. For simplicity, we do not consider the edge types (i.e., single or double bonds) in this example. This figure illustrates that while CCCH and O form a frequently occurring correlated pair of subgraphs, the individual instances (for example, HCC(-O)C) may not be frequent patterns themselves. Therefore, existing frequent subgraphs mining techniques cannot mine such pairs of correlated subgraph patterns.
[Background and Problem] A large body of work exists on mining recurring structural patterns among a group of nodes in the form of frequent subgraphs [1, 2]. However, can we mine recurring patterns among the frequent subgraphs themselves? In this paper, we explored this question by mining correlated pairs of frequent subgraphs. Correlated subgraphs are different from frequent subgraphs due to the flexibility in connections between constituent subgraph instances. To elaborate, in Figure 1, we highlight three regions inside the chemical structure of Taxol, an anti-cancer drug, where CCCH and O occur closely albeit connected in different ways in all three instances. For simplicity, we do not consider the edge types (i.e., single or double bonds) in this example. This figure illustrates that while CCCH and O form a frequently occurring correlated pair of subgraphs, the individual instances (for example, HCC(-O)C) may not be frequent patterns themselves. Therefore, existing frequent subgraphs mining techniques cannot mine such pairs of correlated subgraph patterns.

Figure 1: Correlation between CCCH and
O in Taxol, an anticancer drug. CCCH and O frequently occur closely but can be connected
in multiple different ways.
[Application Scenarios] Correlated subgraphs mining (CSM) will be useful for many applications. For example, it can be used in the identification of co-operative functions in biological networks. In a genome graph of an individual, a node represents a gene and each edge denotes the interaction between two genes. In practice, there are some combinations of dominant genes that co-occur frequently, and these are more likely to express critical phenotypes of the individual. Previous studies show that some pairs of dominant gene combinations co-occur in each individual, and such co-occurring patterns often reflect the joint functionality that is needed for co-operative biochemical functioning such as chemical bonding and binding sites interactions [18]. Based on pairs of correlated genes, we can predict co-operative biological functions of an individual.
To demonstrate the utility of CSM, we present insights derived from the correlated pairs mined in the following datasets.
[Application Scenarios] Correlated subgraphs mining (CSM) will be useful for many applications. For example, it can be used in the identification of co-operative functions in biological networks. In a genome graph of an individual, a node represents a gene and each edge denotes the interaction between two genes. In practice, there are some combinations of dominant genes that co-occur frequently, and these are more likely to express critical phenotypes of the individual. Previous studies show that some pairs of dominant gene combinations co-occur in each individual, and such co-occurring patterns often reflect the joint functionality that is needed for co-operative biochemical functioning such as chemical bonding and binding sites interactions [18]. Based on pairs of correlated genes, we can predict co-operative biological functions of an individual.
To demonstrate the utility of CSM, we present insights derived from the correlated pairs mined in the following datasets.

Figure 2: (a-d) Correlated subgraph pairs <Q1, Q2> and <Q3, Q4> in Yeast. (e) Correlated pair in LastFM. CP denotes Coldplay and RH denotes Radiohead. (f) Correlated pair in Coauthor.
Yeast [19]. The node labels (Gene Ontology
tags) in this Protein Interaction (PPI) network indicate their biological
function. In Figure 2, we present two of the top-10 correlated pairs mined.
Figures 2a (Q1) and 2b
(Q2) show the first
pair. Q1 is constituted
entirely of units specialising in ion binding, and Q2 is composed of those specialising in transferase
activity. Keike et al. [23, 24] have shown that transferases can gain enzymatic
activity following the binding of ionic ligands, undergoing conformational changes
to insulate the ligands from surrounding water molecules. We highlight another
pair < Q3, Q4>
in Figures 2c and 2d. Q3
is made up of genes that handle responses to chemicals and Q4 is associated with
transcription. This co-occurrence is not a coincidence. Specifically, the Gene
Ontology [22] database describes in detail the involvement of positive
transcription regulation in cellular response to chemical stimulus. Finally, we
verified each of the top-10 correlated pairs through domain experts to
determine what percentage of pairs suggested biological correlation. The
experts could not reject any pair as biologically non-linked. In their opinion,
all 10 correlated pairs are either definitely linked, or suggest interesting
correlations requiring further investigation.
LastFM [20]. Figure 2e depicts a correlated pair from the top-k set. This pair showcases that communities of users who like the music band Coldplay, are often in close proximity to communities of users who like Radiohead. These two bands are contemporaries, originate from UK and they are often compared on social media.
Coauthor [21]. Figure 2f presents a pair from the top-10 list in the Coauthor (DBLP) network. Nodes correspond to authors and node labels denote the most frequent publication venue of the authors. In this regard, the presented pair is interesting since it reveals proximity between the networking community (ICCCN) and the architecture community (SIGARCH). While most of the other pairs are between conferences centered on similar areas, this pair shows that there is high collaboration between networking and architecture communities. More importantly, this pair reveals that correlated subgraphs may unearth non-trivial connections between communities.
LastFM [20]. Figure 2e depicts a correlated pair from the top-k set. This pair showcases that communities of users who like the music band Coldplay, are often in close proximity to communities of users who like Radiohead. These two bands are contemporaries, originate from UK and they are often compared on social media.
Coauthor [21]. Figure 2f presents a pair from the top-10 list in the Coauthor (DBLP) network. Nodes correspond to authors and node labels denote the most frequent publication venue of the authors. In this regard, the presented pair is interesting since it reveals proximity between the networking community (ICCCN) and the architecture community (SIGARCH). While most of the other pairs are between conferences centered on similar areas, this pair shows that there is high collaboration between networking and architecture communities. More importantly, this pair reveals that correlated subgraphs may unearth non-trivial connections between communities.
These
case-studies illustrate how our proposed CSM can be useful in
solving real-life problems.
[Challenges and Differences with Related Work]
[Challenges and Differences with Related Work]
Frequent subgraphs mining. Detecting correlated subgraphs is
harder than the frequent subgraphs mining (FSM) problem [1, 2], which already
has an exponential search space (a graph with m edges can have 2m
subgraphs). Techniques have also been developed for discriminative [3, 4],
statistically significant [5, 6, 7, 8, 9] and representative subgraphs mining [10,
11, 12, 13]. For correlated subgraphs mining (CSM), the search space is doubly
exponential (because one needs to compute the correlation between every pair of
subgraph instances). Additionally, unlike FSM, CSM neither exhibits downward
closure nor upward closure, thereby making it difficult to directly apply
apriori-based pruning techniques. Moreover, only mining frequent subgraphs is
not sufficient for our problem. Since we call subgraph A as correlated to
subgraph B if their instances are frequently located close to each other, we
need to enumerate all instances of those frequent subgraphs for computing the
degree of correlation between A and B. This makes our problem more challenging
from both computational and memory consumption perspectives.
Correlated subgraphs mining in graph databases. The
closest related work in the space of correlated subgraphs mining is by Ke et
al. [14]. However, there are two fundamental differences:
(1) Definition of correlation: Ke et al. target the graph
database scenario where there are multiple graphs: two subgraphs A and B are
called correlated if the containment of A within a data graph increases the
likelihood of containing B as well. In our problem, we have only one large data
graph. In this graph, subgraphs A and B are defined to be correlated if the instances
of A are frequently located in close proximity to the instances of B.
(2) Notion of proximity: Owing to the difference in the
definition of correlation, there is no concept of proximity in [14]. In our
problem, for each instance of a subgraph, we need to search and track instances
of all other subgraphs that occur within a user-specified distance threshold.
This operation is the root of the primary computational bottleneck, which does
not arise in [14].
Relaxed notions of frequent subgraphs mining. Our
problem also has similarities with various relaxed definitions for frequent
subgraphs mining and search. For example, proximity patterns [15] were
introduced to mine the top-k set of node labels that co-occur frequently in
neighbourhoods. Correlations between node labels and dense graph structures
were identified in [16, 17]. In our problem, while we allow certain flexibility
in terms of how the constituent subgraph instances are connected, we still
maintain fixed structures for subgraph instances.
[Our Algorithmic Contributions] In spite of the aforementioned challenges and fundamental differences with existing literature, it is still desirable to obtain CSM results within minutes over real networks containing millions of nodes. In this work, we achieve this task with our novel algorithmic contributions.
In particular, the key
differentiating factor in our problem compared to existing subgraphs mining
problems is that we not only need to identify the subgraph patterns, but also
enumerate and store all its instances. This requirement imposes a huge
scalability challenge on both computation and storage. We address this issue by
designing a novel data structure called “Replica”,
which stores all instances of a subgraph pattern on-demand in a compressed
manner. Using Replica as the data storage platform, we design a single-step, best-first
exploration algorithm to detect correlated subgraph pairs efficiently. We also
discuss the novelty of the Replica over existing compressed structures for
various graph mining tasks, as well as its potential applicability in other
workloads. We further speed up the mining process by designing a near-optimal approximation algorithm.
[Reference]
[1] X. Yan and J. Han. “gSpan:
Graph-Based Substructure Pattern Mining”. In ICDM, 2002.
[2] M. Worlein, T. Meinl, I.
Fischer, and M. Philippsen. “A Quantitative Comparison of the Subgraph Miners
MoFa, gSpan, FFSM, and Gaston”. In PKDD, 2005.
[3] X. Yan, H. Cheng, J.
Han, and P. S. Yu. “Mining Significant Graph Patterns by Leap Search”. In
SIGMOD, 2008.
[4] S. Ranu, M. Hoang, and
A. Singh. “Mining Discriminative Subgraphs from Global-state Networks”. In KDD,
2013.
[5] M. A. Hasan and M. J.
Zaki. “Output Space Sampling for Graph Patterns”. PVLDB, 2(1):730–741, 2009.
[6] S. Ranu and A. Singh.
“GraphSig: A Scalable Approach to Mining Significant Subgraphs in Large Graph
Databases”. In ICDE, 2009.
[7] S. Ranu, B. T. Calhoun,
A. K. Singh, and S. J. Swamidass. “Probabilistic Substructure Mining From
Small-Molecule Screens”. Molecular Informatics, 30(9):809–815, 2011.
[8] S. Ranu and A. K.
Singh. Mining Statistically Significant Molecular Substructures for Efficient
Molecular Classification. Journal of Chemical Information and Modeling,
49:2537–2550, 2009.
[9] S. Ranu and A. K. Singh.
Indexing and Mining Topological Patterns for Drug Discovery. In EDBT, 2012.
[10] M. A. Hasan, V.
Chaoji, S. Salem, J. Besson, and M. J. Zaki. “ORIGAMI: Mining Representative
Orthogonal Graph Patterns”. In ICDM, 2007.
[11] S. Zhang, J. Yang, and
S. Li. “RING: An Integrated Method for Frequent Representative Subgraph Mining”.
In ICDM, 2009.
[12] D. Natarajan and S.
Ranu. “A Scalable and Generic Framework to Mine Top-k Representative Subgraph
Patterns”. In ICDM, 2016.
[13] S. Ranu, M. Hoang, and A.
Singh. “Answering Top-k Representative Queries on Graph Databases”. In SIGMOD,
2014.
[14] Y. Ke, J. Cheng, and J. X.
Yu. “Efficient Discovery of Frequent Correlated Subgraph Pairs”. In ICDM, 2009.
[15] A. Khan, X. Yan, and K.-L.
Wu. “Towards Proximity Pattern Mining in Large Graphs”. In SIGMOD, 2010.
[16] Z. Guan, J. Wu, Q. Zhang,
A. Singh, and X. Yan. “Assessing and Ranking Structural Correlations in Graphs”.
In SIGMOD, 2011.
[17] A. Silva, J. W. Meira, and
M. J. Zaki. “Mining Attribute-structure Correlated Patterns in Large Attributed
Graphs”. PVLDB, 5(5):466–477, 2012.
[18] E. A. Lee, S. Fung, H.
Sze-To, and A. K. C. Wong. “Discovering Co-occurring Patterns and their
Biological Significance in Protein Families”. BMC Bioinformatics, 15(S-12):S2,
2014.
[23] R. Koike, T. Amemiya, M.
Ota, and A. Kidera. “Protein Structural Change upon Ligand Binding Correlates
with Enzymatic Reaction Mechanism”. Journal of molecular biology, 379:397–401,
07 2008.
[24] R. Koike, A. Kidera, and M. Ota. “Alteration of
State and Domain Architecture is Essential for Functional Transformation
between Transferase and Hydrolase with the Same Scaffold”. Protein Science: a
Publication of the Protein Society, 18:2060–6, 10 2009.

All thanks to Mr Anderson for helping with my profits and making my fifth withdrawal possible. I'm here to share an amazing life changing opportunity with you. its called Bitcoin / Forex trading options. it is a highly lucrative business which can earn you as much as $2,570 in a week from an initial investment of just $200. I am living proof of this great business opportunity. If anyone is interested in trading on bitcoin or any cryptocurrency and want a successful trade without losing notify Mr Anderson now.Whatsapp: (+447883246472 )
ReplyDeleteEmail: tdameritrade077@gmail.com